

每当经济学发生重大转向,许多“时尚”的新方法和工具会被加入经济学家的豪华工具包。学者期待热门新工具的出现能拓展经济学的前沿。而亦有人认为,新工具也带来了新风险,甚至可能导致歧途,特别是在初期。
今日,我们组织编译了一篇关于经济学趋势及最新工具的最新文章,涉及经济学的数据革命、准实验法、及机器学习的渗透。其中,纽约州立大学金融学教授Noah Smith 简明生动地探讨了经济学的趋势,而斯坦福大学经济学教授、微软顾问Susan Athey 则基于丰富的经验分析机器学习在经济学的应用与前景。
诚然,经济学界从未停止对于新趋势或工具的“争论”。不过,对于短暂狂热的批评有一点是对的:好的经济学是要提出正确的问题,而经济学所有工具中,实践者的怀疑才是最永恒的。
数据怪咖开始接管经济学
Noah Smith,Stony Brook University
过去几十年,经济学家习惯于思忖世界的运作规则,并写下一套理论阐述自己的观点,然后就收工大吉。如果一些统计学家正好为该理论找到了佐证,那再好不过了!不过,通常他们找不到相关佐证,但这样也无所谓。正如一个老笑话所言,如果一个想法能付诸实践,那么经济学家会问它是否在理论上可行。
正如我彭博社同事Justin Fox的记录,这种现象在20世纪80年代至90年代开始发生转变,当时经济学开始转向实证研究领域:
经济学研究性质的转向
顶级经济学期刊中的文章方法所占百分比
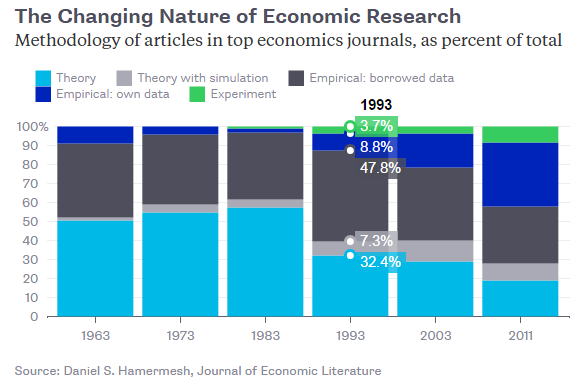
这一转变的关键在于,实惠的信息技术爆发式的发展使得收集与分析数据更为便利。90年代,存在大量未经证实的理论及丰富的新数据,这使得聪明的年轻经济学家将精力转向实证研究方向。在物理学中,理论与实验需要具备截然不同的一套技能,但大多数经济学家发觉他们从理论转向数据则相对简单。权威奖项开始对一些人垂青有加,比如奖励40岁以下经济学新星的克拉克奖,这些青年学者的研究注重数据与实践运用。
然而,在这一进程中出现了第二次转向——所谓的经济学中数据革命的第二阶段。实证经济学家的工具开始转变,这可能会改变经济学家如今所运用的种种理论。
如今,经济学理论的核心是基于个人最优假设。比如,经济学家通常假设商业活动会实现利润最大化或成本最小化。这被称为结构模型,因为经济学家通常认为这类最优化代表了深沉次,根本的经济结构,正如你身体的任何部分都是有原子与分子构成。将这类模型与数据对照则是所谓的结构推测,这以往构成了实证经济学的核心。
但是结构性推测有所局限。由于结构模型通常非常复杂,对于“如果提高最低工资标准,多少人对面临失业?”这类简单的问题,该模型得出的结论往往受限于模型的假设。倘若微调一个假设条件,就可能得出完全错误的结论。
因此,许多经济学家近年来已经开始寻求其它的方法,完全将理论剥离开来。他们不再采用复杂的最优与效用函数模型,而是仅着眼于所谓的自然实验,即经济中的某些偶然变化为重要问题的研究打开一扇窗。比如,你可以研究一批偶然涌入的难民,以回答移民如何影响当地劳动力市场等问题。你不需要一个关于工人与企业行为的复杂模型,只需建立关于X如何影响Y的简单线性模型。
这种方法的主要转播者是经济学家Joshua Angrist与Jörn-Steffen Pischke.他们将自然实验的兴起或所谓的准实验法称为“可信性革命”,出版了一本关于该话题的书,名为《基本无害的计量经济学》。由于准实验法(quasi-experiment)比结构模型更为简洁可行,该方法对于我们所提的重要问题不太会给出错误的结论。
基于对以往实证研究存在的问题进行探讨,Angrist与Pischke认为更多更好的数据和更好的研究设计是进行实证研究的关键。在各国的官方数据以及调查数据逐步增加的情况下,良好的研究设计对实证研究者来说尤为重要。他们指出,随机实验是最可信和最有影响力的研究设计,从80年代起,经济研究者就开始寻求随机实验数据以期求证因果关系。
随机实验设计虽然能够得到最可信和最有影响力的结果,但是其投入成本是非常大的,研究者很难得到可靠有用的随机实验数据的集合。在随机实验数据不可得的情况下,Angrist和Pischke认为可以寻找经过良好控制的对照组,因此,准实验研究设计成为最好的选择。最为常用的准实验研究设计的方法有工具变量、断点回归法、双差分。
到目前为止,革命节节胜利。正如经济学家Matthew Panhans与John Singleton在近期论文的统计显示,准实验法相关研究的学术出版率越来越高。他们搜索了包含该方法相关术语的文献,发现这些术语相比20多年前更为普遍:
准实验法在经济学杂志中的运用
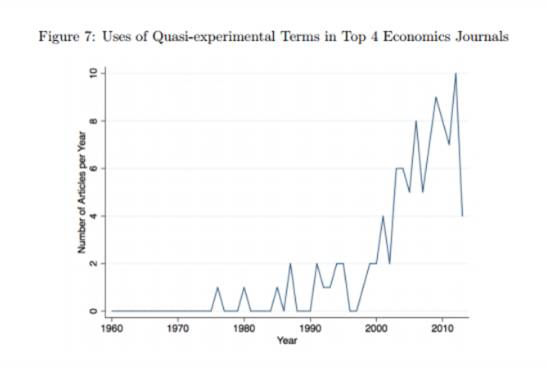
虽然这还是算经济学文献的少数派,但增长速率还是很惊人的。准实验法的相关研究结论似乎引起了政界与媒体更为广泛的关注与曝光。这可能是由于复杂的结构模型很容易遭受质疑——只需要质疑一个或两个相关假设(无疑不切实际)。同时,准自然实验所涉及的数学相对简单,大多数人更好理解。
赶“时髦”?机器学习最时尚
去年1月,当美国经济学会年会上的博士生就业时,那个场面用“赶集”来形容最贴切不过了。或者说,按照最新的经济学论文的“流行”趋势来看,这些新毕业生好像是“羊群”跟风一般。要知道,当前热门的经济学工具是机器学习,伦敦大学学院经济学教授Imran Rasul正等着阅读一堆使用这种时髦工具的论文。
经济学者对学术方法的追求有时几近疯狂。Rasul回忆起以往的大批论文,倾向于运用断点回归法。据《经济学人》的统计,发表于美国国家经济研究局(NBER)的工作论文涉及的关键词显示了经济学者对实验室实验,随机对照试验(RCT)和差异差异方法(即,比较不同组之间随时间的趋势)的热情。
“时髦”的捅趸者;NBER工作论文摘要中涉及方法所占百分比
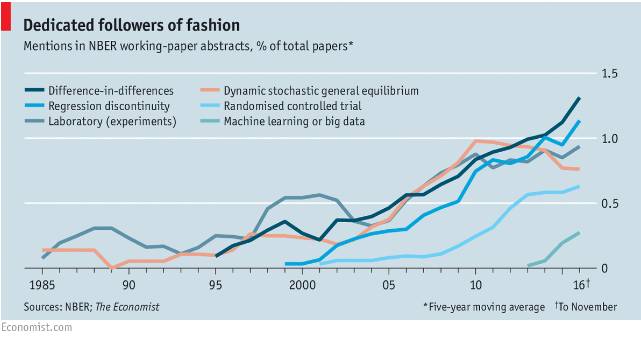
当一个热门的新工具出现时,它应该能拓展经济学的前沿,并将以前无法回答的问题拉近视野。不过,一些经济学家认为新的方法也带来了新的危险;疯狂可能导致歧途,而不是推动经济前进,特别是在起步阶段。
原则上,这些新工具应该使得经济学家免受自己草率的理论构建之苦。之前,经济学家会尝试用少数参数输入,来预测事物。通过机器学习,数据可以不言自明; 机器学习知道哪些参数输入能产生最准确的预测。这种强大的方法似乎提高了经济学家预测的准确性。
例如,研究人员已经开始用大数据来预测犯罪嫌疑人是否会回到法庭接受审判,从而影响保释决定。但是,与RCT一样,强大的算法可能会致使用户忽视深层次的诱因。数据科学家Cathy O'Neil在她的新书《数学破坏武器》中指出,一些因素,如种族或来自高犯罪行为的社区,可能是再犯罪的极好预测因素。但他们可以反映种族主义在执法或零容忍的“破窗”政策中,导致贫穷或少数民族社区的高犯罪率。
斯坦福大学的Susan Athey教授则看重机器学习在经济学领域的运用潜力。她是第一位获得克拉克奖的女性经济学家,并作为斯坦福商学研究生院科技经济学教授、微软顾问,在经济学与科技领域深度融合方面颇有建树。她近日在Quora撰文,论述机器学习对经济学的影响:
Susan Athey, Stanford University
我认为,机器学习将对经济学产生巨大的影响。初期,计量经济学家往往采用“现成”的方法,而长远来看,他们会改进相关方法并使得其满足社会科学家的需求。社科学家主要研究兴趣在于因果关系推断和反事实政策影响估测,后者指还未尝试的事情,或如何采取不同政策会发生什么。经济学家对此类问题的研究例子不胜枚举,如价格变更、差别定价、最低工资变化等影响或广告效果的评估等。我们想要估测变化可能带来什么,或者变化未能发生可能产生的后果。
其实,这一影响已经悄然发生了。去年夏天,有 250名经济学教授在一个周六下午参加了我和Guido Imbens组织的一个NBER研讨会,会上我俩为在座的经济学家讲授机器学习的内容,每当我在经济学家面前做这方面的演讲,都会吸引大批听众。我想,少数进行该领域研究的其它经济学家也与我有相同的经历。几周前,有好几百人参加了美国经济学会举办的大数据会议。
机器学习是一个宽泛的术语,在此我将聚焦该领域的两三方面。机器学习有两大分支,监督和非监督型机器学习。监督学习通常运用一系列“特征”或“协变量”(x’s),去预测相关结果(Y)。现在有各种机器学习的方法,比如 LASSO(参见MIT教授Chernozhukov与其合著者的研究,他们将该方法引入经济学领域)、随机森林,回归树、支持向量机等。
许多机器学习方法有一个共同的特点,都采用交叉检验法来选取模型复杂性;即,反复用一部分数据估测一个模型,然后用另一部分数据来验证模型,最终找到所谓的"复杂性惩罚项",用预测的均方误差衡量(模型预测与实际结果之间的方差),该项与数据的拟合度最高。
在大多数截面计量经济学中,一般是研究者制定一个模型,而后通过对比2-3个代替模型检验该模型的“稳健性”。我相信,随着我们更频繁地接触存在许多协变量组的数据集,并且明白系统性模型选择的优势,正规化和系统模型的选择将成为经济学实证实践的标准。
哈佛大学Sendhil Mullainathan、Jon Kleinberg及一众合著者认为,既有的机器学习预测方法作为重要政策和决策问题的一部分时,会产生一系列问题。他们举了一些例子,比如是否要为年长的患者实施髋关节置换术;如果能基于他们个人的状况,预测患者会在一年内去世,那么你就不应该实施手术。
对于被关押等待审判的犯人,如果能预测谁将出庭,当局就可以让更多其他犯人获得假释。机器学习目前被用在一系列司法程序中的这类决策上。几周前,Goel, Rao and Shroff 在美国经济学会的会议上宣讲了一篇论文,该论文用机器学习法分析警察在路边的拦截盘查问题。我在“预测城市”会议期间宣讲的内容,也讨论了机器学习在公共部门的使用。
除了这些令人着迷的例子外,机器学习预测模型一般建立在与大量社科工作中因果推测根本对立的前提下。监督学习方法的基础是进行模型选择(交叉验证)以优化测试样本的拟合优度。当且仅当预测准确时,模型才是有效的。然而,计量经济学导论的基石是预测并非因果推论;一个经典的经济实例,即价格和数量在许多经济数据集中都呈正相关。
在消费者购买力更高的高收入城市,公司的定价会更高;他们提高价格,是基于需求高峰的预期。大量的计量经济学研究旨在降低模型的拟合优度,以便估计价格变动的因果效应。如果价格和数量在数据中是正相关的,任何估计真正因果效应的模型(如果你改变价格,数量会下降)就不会那么好地拟合数据。在预测企业在特定时间点实际改变价格会有何后果时,涵盖因果估计的计量经济学模型更为适用——总之,该模型更适用于在世界变化时做出反事实预测。
像工具变量等方法只能使用数据中的一些信息,如价格中的“净价”、“外生”或“实验性”的变化,牺牲当前环境中的预测精度,以了解有助于价格变化决策的更深层次关系。这种模式在机器学习中几乎没有受到任何关注。
在一些研究中,我正在探索是否可以利用机器学习法的优点和创新,但想将其应用于因果推断。这需要改变目标函数,因为在任何测试集中无法观察到因果参数的地面真值(ground truth, ML terms)。要统计理论发挥更大的作用,我们就需要建立一个估计无法观察事物的模型(因果效应),以便定义算法优化的目标。
我也正在为一些广为运用和最为成功的估计量(如随机森林)研究一套统计学理论,并对其进行调整,以便将理论用于预测个体的统计处理效果。例如,通过基于回归树或随机森林的方法,我可以基于人们各自的特点,揭示特定的个体会如何对价格变化做出反应。不过,这也存在置信区间。我还写了一篇关于使用机器学习方法来系统地检验因果估测稳健性的论文,并于去年发表在《美国经济评论》上。我希望这类方法有些可以运用到实践中,去评估随机对照试验,科技公司的A / B测试等,从而发现系统异质性处理的效果。
无监督学习工具与监督学习的不同在于,前者没有结果变量(无“y”):这些工具可用于查找类似对象集群,它们通常用于对图像或视频进行分组。我在自己的研究中使用了这些工具来找类似主题的新闻文章。比如,一个计算机科学家在YouTube上发现了猫,这可能意味着他们使用无监督的机器学习方法找到一组相似的视频。我认为这些工具作为实证研究的中间步骤非常有用,因为他们能以数据驱动方式来查找类似的文章、评论、产品、用户历史等。
随着时间的推移,不同经济学方法和工具的优点或局限性将得到更好的体现,它们将与旧方法一起加入经济学的工具包。然而,对于短暂狂热的批评有一点是对的:好的经济学是要提出正确的问题,而在经济学所涉及的所有工具中,践者的怀疑主义才是最永恒的。
学者名片






编译:金颖琦; 翻译整理自Data Geeks AreTaking Over Economics,Noah Smith, Bloomberg; How will machine learning impact economics?, Susan Athey, Quora; 参考Economists are proneto fads, and the latest is machine learning, The Economist.

